


SQL Subqueries: A Comprehensive Guide
Everything you need to know about SQL Subqueries

Hey Friend,
Today I’m sharing with you everything I know about a very important SQL technique: Subqueries! It's a great tool if you are writing complex queries in SQL. So let’s go!
What are Subqueries?
In its simplest form, a subquery is a query embedded within another query. It’s like a mini-query that helps the main query achieve a specific task, whether it’s filtering data, calculating aggregates, or joining tables.
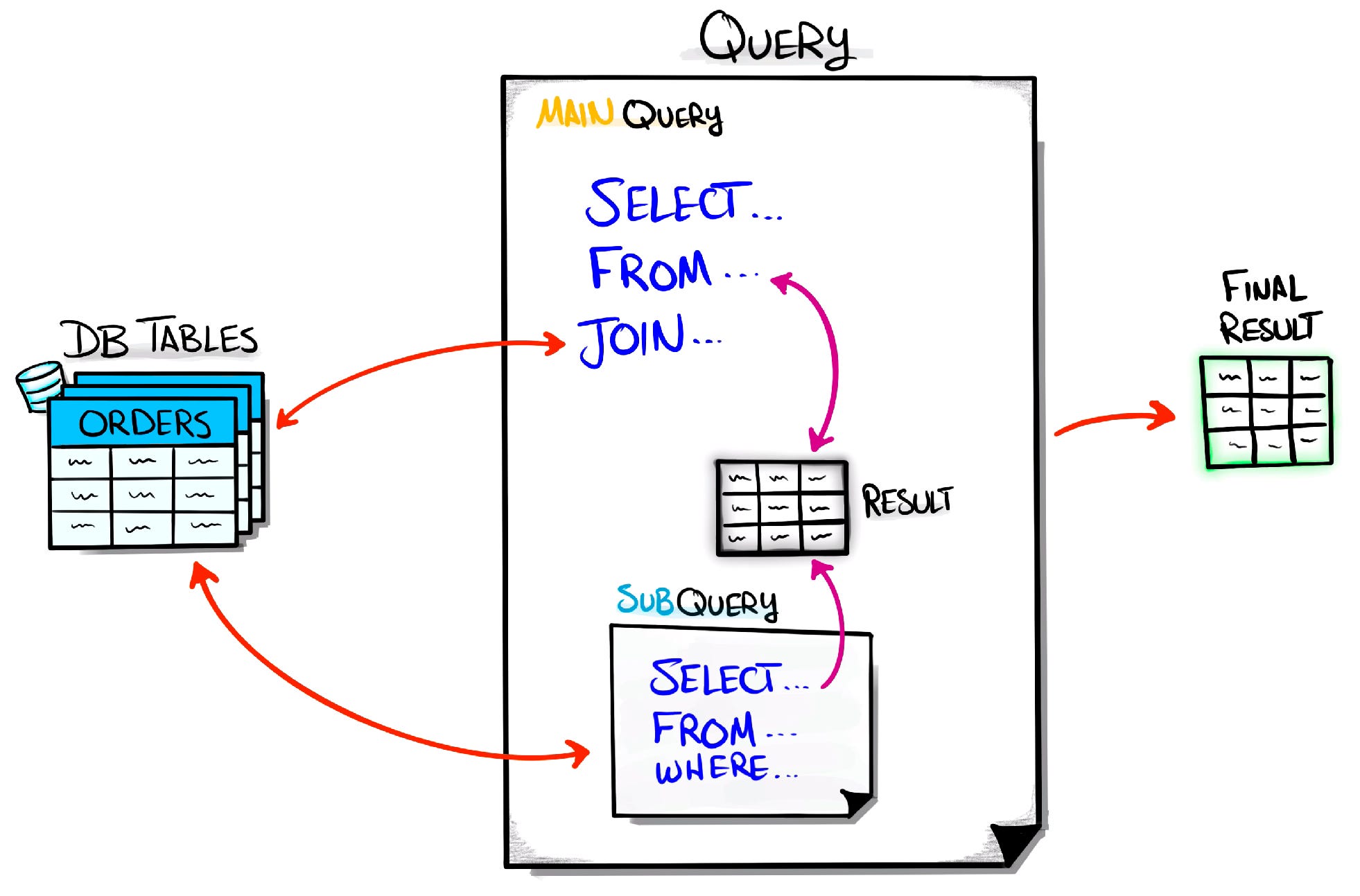
Why Use Subqueries?
Subqueries are super handy when you need to handle complex tasks that involve multiple steps. Let’s say you want to join tables, filter some data, transform it, and then sum it all up. Instead of writing one long, confusing query, you can break it down with subqueries. Each subquery tackles a specific part of the job, making your main query cleaner and easier to understand.

Types of Subqueries
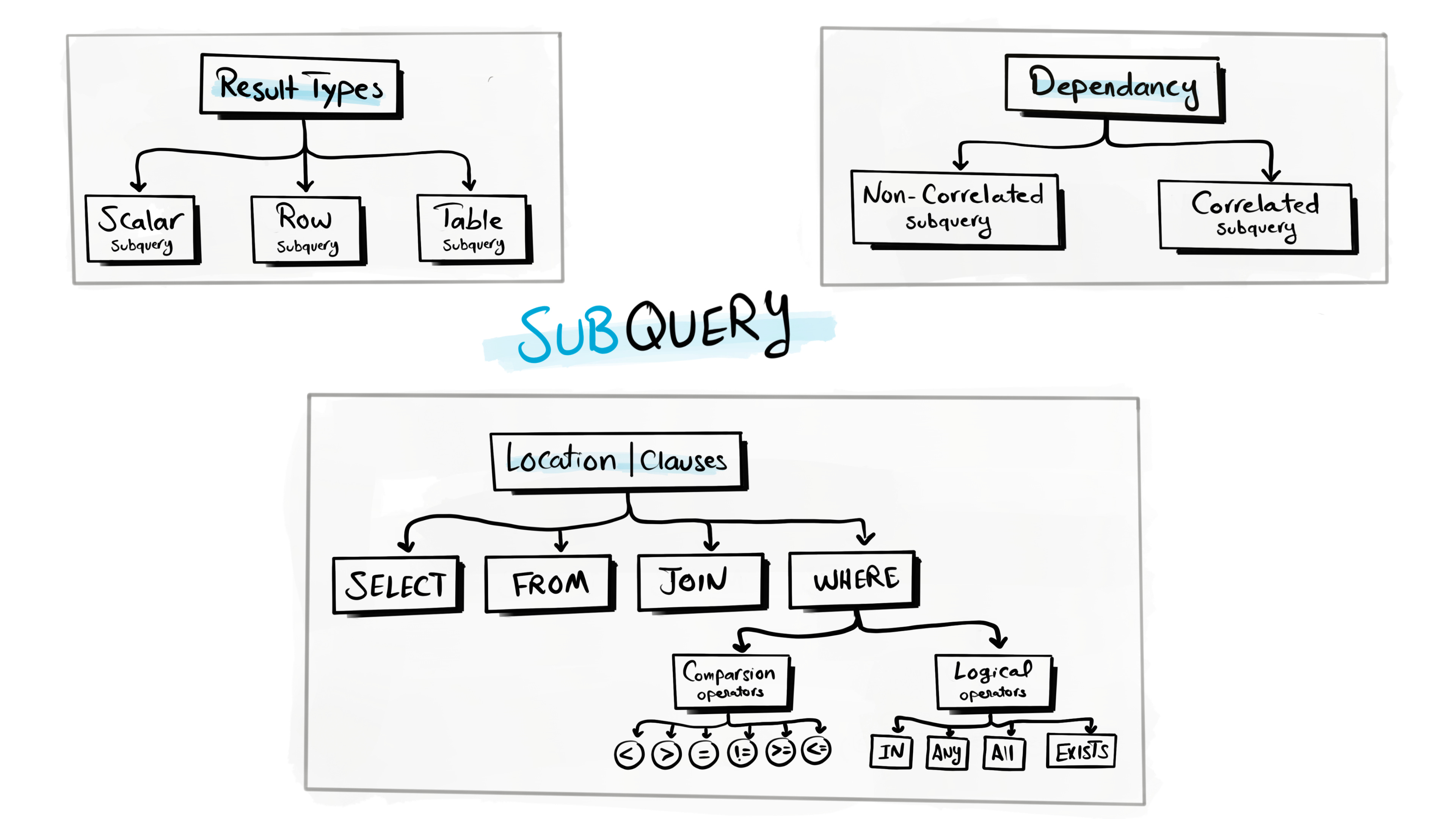
Subqueries come in different forms depending on their output and how they relate to the main query:
Scalar Subquery: Returns a single value, like the average of a column.
Row Subquery: Returns multiple rows but only one column.
Table Subquery: Returns a full table with multiple rows and columns.
Subquery Locations in SQL
You can drop subqueries into different parts of your SQL statements, such as:
FROM Clause: To create temporary result sets that work like tables.
SELECT Clause: To calculate values alongside the main query's columns.
JOIN Clause: To prepare data before joining tables.
WHERE Clause: To filter data using dynamic conditions.
Correlated vs. Non-Correlated Subqueries
Non-Correlated Subquery: Stands alone and runs just once, independent of the main query.
Correlated Subquery: Depends on the main query and runs for each row that the main query processes.

Operations used with Subqueries
Comparison Operators - (like
=,>,<) for comparing valuesIN - for checking if a value exists in a list
ANY- for testing if any value in a list meets a condition
ALL - for ensuring all values in a list meet a condition
EXISTS - for checking if any rows are returned by a subquery.
My Final thoughts about Subqueries
When I’m working on projects, I follow these best practices for subqueries:
Limit Subquery Use: Prefer using JOINs or CTEs over subqueries when you can.
Use EXISTS Instead of IN: EXISTS tends to be faster with large datasets.
Be Cautious with Correlated Subqueries: They can slow down your query.
Explicitly Handle NULLs: Make sure you’re managing NULL values correctly.
Avoid Scalar Subqueries in SELECT: For better performance, use JOINs or APPLY instead.
And there you have it! Subqueries might seem tricky at first, but with a little practice, they’ll become your go-to solution for streamlining complex queries. I hope you found this helpful, and if you have any questions or want to share your own tips, I’m all ears! Happy querying!
Baraa

Hey friends —
I’m Baraa. I’m an IT professional and YouTuber.
My mission is to share the knowledge I’ve gained over the years and to make working with data easier, fun, and accessible to everyone through courses that are free, simple, and easy!